Araneae
This is a python3 program that works as a Wikipedia crawler and utilizes BeautifulSoup and the requests modules. It goes through the entire Wikipedia page of the user entered URL and stores the information available on the wikipedia page as a .txt file on the system locally.
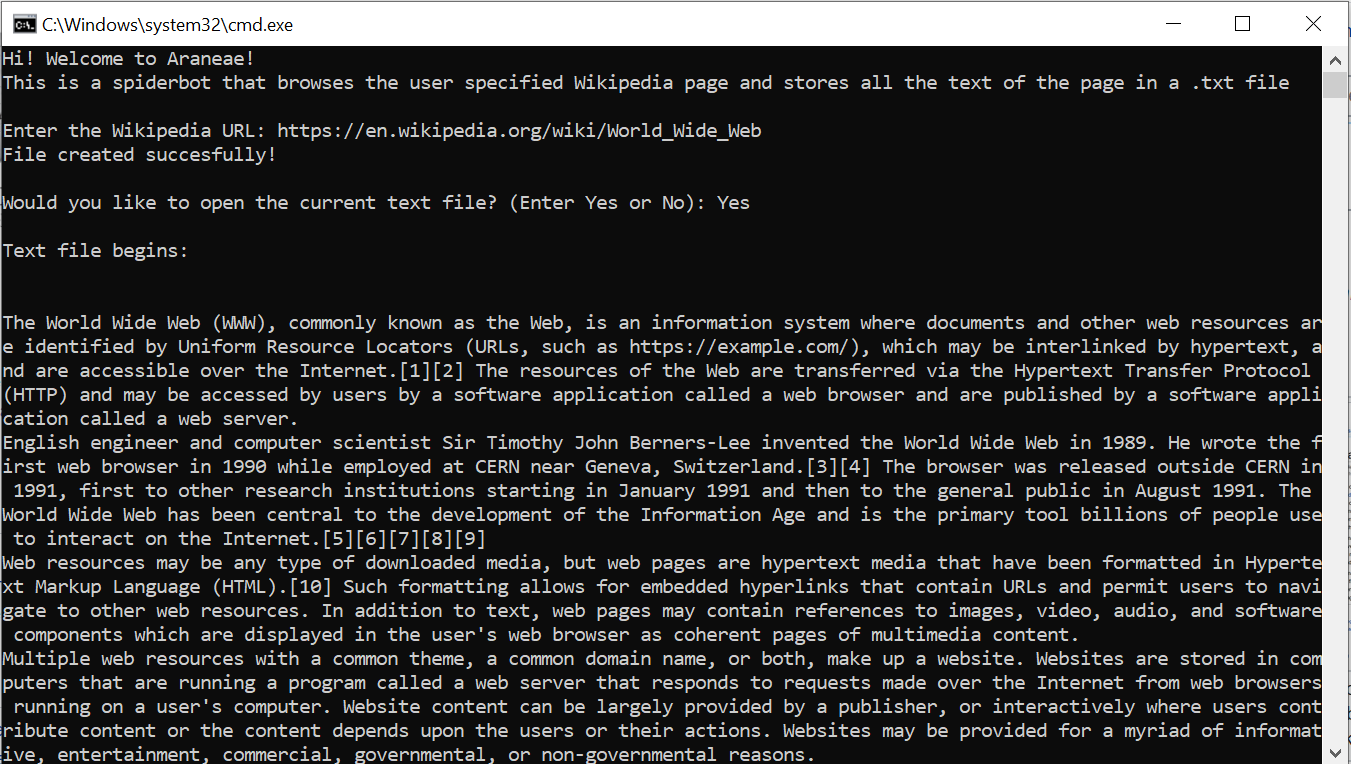
Setup
Installation
- Install
Python 3.7or above. - Install these modules:
- requests
- bs4
Running the program
- Download the
Crawler.pyfile. - Open the folder containing the aforementioned file in your terminal (for MacOS and Linux) or command prompt (for Windows).
- Type
python Crawler.pyand press enter to run the program.
OR
- Install any IDE.
- Create a new project, copy the
Crawler.pycode and paste it in a.pyfile. - Run the program.
Contributing
Pull requests are welcome for adding more feautures or fixing exisiting issues.